OMV Images
ROCKPro64
3
Beiträge
1
Kommentatoren
1.0k
Aufrufe
-
OMV (https://www.openmediavault.org/) ist ein Betriebssystem mit Oberfläche, das es erlaubt einen PC als NAS zu konfigurieren. Ein entsprechendes Image hat Kamil im Angebot.
Unser @tkaiser bietet auch selbst zusammen gestellte Images an, die wohl zu einem großen Teil auf Armbian basieren. Hier kündigt er ein solches an.
Außerdem, geht er davon aus das wir in naher Zukunft auch ein Armbian für den ROCKPro64 bekommen.
Vielfalt belebt das Geschäft
")
-
Ich habe mal testweise das OMV Image vom Kamil installiert.
OMV Version 4.1.8.2-1 (Arrakis) Linux 4.4.132-1072-rockchip-ayufan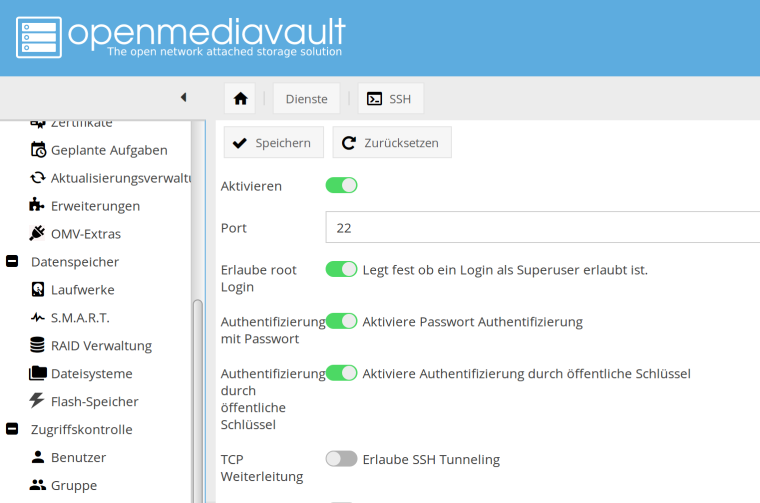
Für den SSH Zugriff als Root ist die Option "Erlaube root Login" einzuschalten.
Nein, das ist keine gute Idee. Aber ist hier nur ein Testsystem!
Gut, OMV zu erklären würde wohl den Rahmen hier sprengen. Ich zeige einfach ein paar Screenshots.
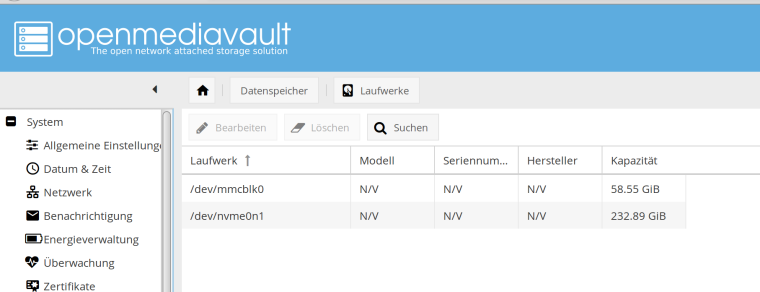
NVMe Laufwerk am PCIe Adapter einwandfrei erkannt.
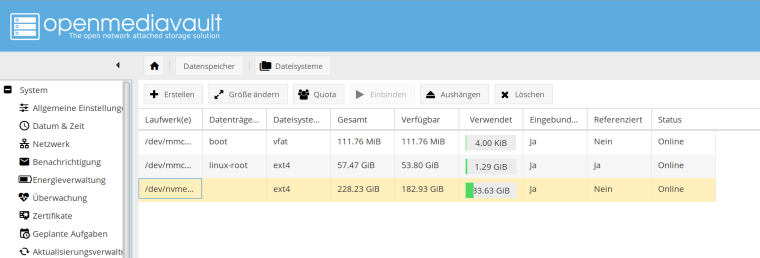
Zum Mounten muss man einmal auf Einbinden klicken. Bleibt das auch nach einem Reboot erhalten? Ja, bleibt es natürlich
Eine NFS-Freigabe anlegen ging problemlos. Nur das Einbinden in meinem Sys wollte nicht so richtig, irgendwas mit Benutzerrechten. Ist jetzt aber mal gar kein ROCKPro64 Problem..
Wer ein kleines NAS aufsetzen will, ist mit dem OMV gar nicht schlecht dran. Dürfte für die meisten alleine schon wegen der grafischen Benutzeroberfläche interessant sein. Ich liebe es ja mittlerweile alles auf der Konsole zu machen, aber es gibt eine Menge Leute die sich damit nicht auseinandersetzen wollen. Ok, für die gibt es OMV
")
-
Kurzes Update
Startet
Incl. WiFi & PCIe NVMe SSDWar aber nur ein ganz kurzer Test!!