Raid1 - Platte verschwunden!?
-
Für die Raid-Experten unter Euch, das was ich hier aufgeschrieben habe ist absolutes Einsteigerwissen!
An alle! Bitte nutzt das hier auf keinen Fall auf irgendeinem produktiven System. Holt Euch da lieber professionelle Hilfe!
Hier mal was, was bei meiner ganzen Spielerei so alles passieren kann. Da ich ja über die Tage versucht habe, das NAS von mir auf ein Armbian zu bringen, ist mir dann irgendwann in meinem check_mk aufgefallen, das das RAID 1 nicht mehr gut aussieht

Ok, Ruhe bewahren. Ich hatte eben noch ein Backup mit Restic gemacht, also alles kein Problem. Dann schauen wir uns das mal an.
Status
So, habe ich das Raid 1 vorgefunden.
rock64@rockpro64v_2_1:~$ sudo mdadm --detail /dev/md0 /dev/md0: Version : 1.2 Creation Time : Sat Oct 20 09:05:51 2018 Raid Level : raid1 Array Size : 1953379392 (1862.89 GiB 2000.26 GB) Used Dev Size : 1953379392 (1862.89 GiB 2000.26 GB) Raid Devices : 2 Total Devices : 1 Persistence : Superblock is persistent Intent Bitmap : Internal Update Time : Wed Dec 26 13:59:23 2018 State : clean, degraded Active Devices : 1 Working Devices : 1 Failed Devices : 0 Spare Devices : 0 Consistency Policy : bitmap Name : rockpro64v_2_1:0 (local to host rockpro64v_2_1) UUID : 33ac7964:473fe590:3682dd85:a979b336 Events : 56050 Number Major Minor RaidDevice State 0 252 0 0 active sync /dev/dm-0 - 0 0 1 removedRaid 1 besteht nur noch aus einer Platte. Irgendein Test hatte dann über einen fehlenden Superblock auf der ersten Platte gemeckert. Ok, schon mal ein Anhaltspunkt. Nach ein wenig Recherche, man ist ja kein Raidexperte
") , ging es dann an die Arbeit.
, ging es dann an die Arbeit.Raid stoppen
rock64@rockpro64v_2_1:~$ sudo mdadm --stop /dev/md0 mdadm: stopped /dev/md0Superblock Nullen
rock64@rockpro64v_2_1:~$ sudo mdadm --zero-superblock /dev/mapper/raid_pool0Raid 1 wieder starten
rock64@rockpro64v_2_1:~$ sudo mdadm --assemble --scan mdadm: /dev/md/0 has been started with 1 drive (out of 2).Zustand
rock64@rockpro64v_2_1:~$ cat /proc/mdstat Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10] md0 : active (auto-read-only) raid1 dm-1[1] 1953379392 blocks super 1.2 [2/1] [_U] bitmap: 5/15 pages [20KB], 65536KB chunk unused devices: <none>Laufwerk wieder hinzufügen
rock64@rockpro64v_2_1:~$ sudo mdadm --add /dev/md0 /dev/mapper/raid_pool0 mdadm: added /dev/mapper/raid_pool0Danach syncen die Laufwerke - das kann dauern!
rock64@rockpro64v_2_1:~$ watch cat /proc/mdstat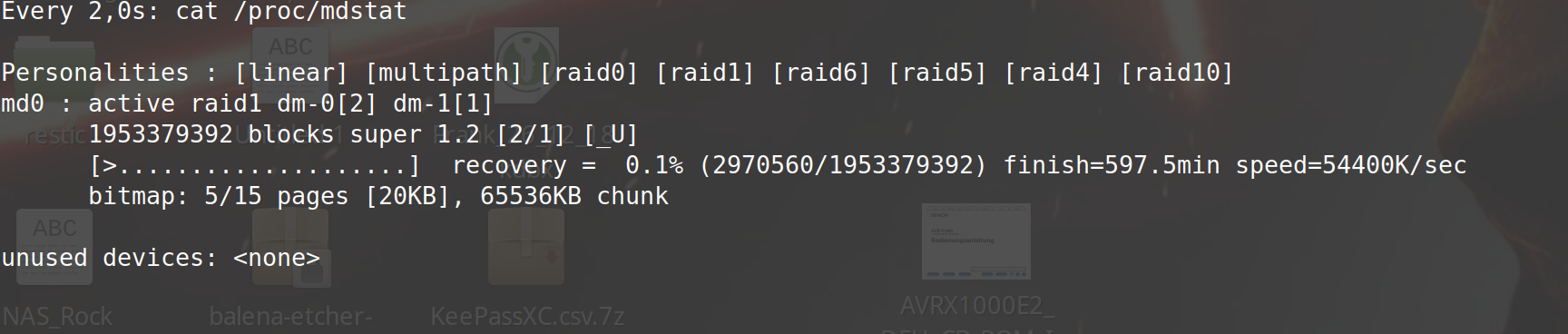
Ob es klappt? Keine Ahnung - lassen wir uns überraschen!
Ca. 10 Stunden später war der Sync angeschlossen. So konnte ich heute Morgen nachschauen, ob ich auch die richtige Platte erwischt hatte. So, mal vorsichtig nachschauen.
root@rockpro64_NAS:~# cat /proc/mdstat Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10] md0 : active raid1 dm-1[1] dm-0[2] 1953379392 blocks super 1.2 [2/2] [UU] bitmap: 0/15 pages [0KB], 65536KB chunk unused devices: <none> root@rockpro64_NAS:~# mdadm --detail /dev/md0 /dev/md0: Version : 1.2 Creation Time : Sat Oct 20 07:05:51 2018 Raid Level : raid1 Array Size : 1953379392 (1862.89 GiB 2000.26 GB) Used Dev Size : 1953379392 (1862.89 GiB 2000.26 GB) Raid Devices : 2 Total Devices : 2 Persistence : Superblock is persistent Intent Bitmap : Internal Update Time : Thu Dec 27 06:57:26 2018 State : clean Active Devices : 2 Working Devices : 2 Failed Devices : 0 Spare Devices : 0 Name : rockpro64v_2_1:0 UUID : 33ac7964:473fe590:3682dd85:a979b336 Events : 57882 Number Major Minor RaidDevice State 2 253 0 0 active sync /dev/dm-0 1 253 1 1 active sync /dev/dm-1 root@rockpro64_NAS:~#Sieht gut aus, der Zustand ist wieder clean. Nicht über den anderen Benutzer wundern, ich habe mittlerweile wieder auf Armbian gewechselt. Im Moment sieht alles wieder gut aus, ich werde da die nächsten Tage aber mal ein Auge drauf haben. Die Frage warum das passiert ist?
Ich denke, das ich was falsch gemacht habe, wie ich das erste mal Armbian genutzt habe. Dort gibt es ja am Anfang kein Device md0.
Ich hatte wohl ein
mdadm --assemble md0 /dev/sda1 /dev/sdb1gemacht. Dabei hatte ich wohl eine falsche Platte erwischt. Durch die USB3-Platte ist da was durcheinander gekommen. ABER, das ist alles reine Spekulation, genau weiß ich das nicht mehr.
Man muss das mit
mdadm --assemble --scanmachen.
Zum Schluss
An einem Raid 1 rumzuspielen ist kein Vergnügen
") Das dauert alles so lange und man weiß vorher nicht immer ob es auch klappt (also ich).
Das dauert alles so lange und man weiß vorher nicht immer ob es auch klappt (also ich).Wer gravierende Fehler feststellt, bitte in die Kommentare damit ich das entsprechend ändern kann. DANKE!
Die /dev/mapper/ Devices die ich benutze kommen davon, das die HDDs verschlüsselt sich. Bei einem unverschlüsselten System nutzt man dann halt die normalen Device Bezeichnungen!