Portainer - NodeBB Container erstellen
Linux
1
Beiträge
1
Kommentatoren
353
Aufrufe
-
Ich habe gestern sehr lange mit Stacks rum gespielt, bin da aber ein wenig verzweifelt

Ok, heute Morgen nach dem ersten Kaffee dann mal mit frischen Kräften ans Werk. Als erstes habe ich mich mal von Stacks entfernt, dazu fehlen mir im Moment zu viele Basics. Also, suche ich mir einen passenden Container und siehe da ich habe sehr schnell einen gefunden.
Nils hat auch eine sehr schöne Anleitung dazu erstellt. Der Container beinhaltet NodeBB und auch direkt eine Redis Datenbank Installation. Der Startaufruf des Containers lautet
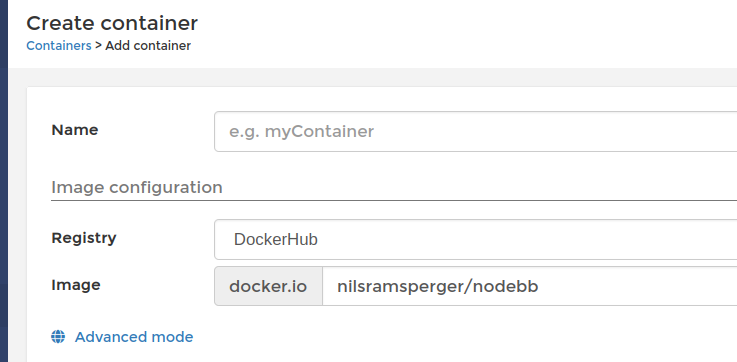
docker create --name myNodeBB --init --restart always -p 4567:4567 -v nodebb-data:/var/lib/redis -v nodebb-files:/opt/nodebb/public/uploads -v nodebb-config:/etc/nodebb nilsramsperger/nodebbDas möchte ich jetzt mal mit dem Portainer grafisch umsetzen. Wir geben dem Container einen Namen und wählen das Image aus.
Wir geben dem Container die angezeigten Ports. Das Forum wird später darüber erreichbar sein. Normalerweise schaltet man einen Proxy (z.B. nginx) davor, damit das Forum ganz normal erreichbar ist. Das soll hier jetzt aber nicht das Thema sein.

Restart Policy einstellen.

Danach hier

diese Volumes erstellen. Damit sichert man die wichtigsten Daten permanent auf dem Host. So mit kann man die Daten auch speichern und der Container startet beim nächsten Start dann auch mit diesen Daten!
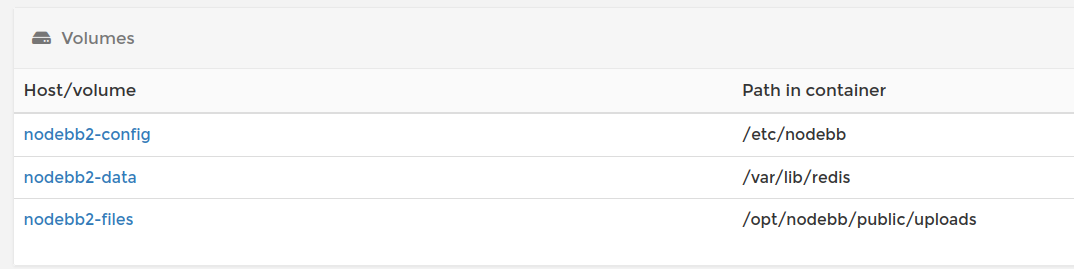
Dann den Container Deployen. Wenn man ihn jetzt aufruft
http://<IPv4>:4567kommt man zum Installationsscreen. Dort legt man den Admin an und die Datenbankverbindung. Ein hier eingegebenes PW für die Datenbank wird nicht beachtet.
node_redis: Warning: Redis server does not require a password, but a password was supplied.Mit dieser Installation kann man relativ einfach ein NodeBB-Forum betreiben. Man kann auch alles einstellen, Plugins installieren, Fotos hochladen usw. Die Daten sind auch nach einem Neustart wieder vorhanden.
Update:
Das mit dem fehlenden PW von Redis ist kein Problem. In der Redis Dokumentation steht dazu folgendes.
Unfortunately many users fail to protect Redis instances from being accessed from external networks. Many instances are simply left exposed on the internet with public IPs. For this reasons since version 3.2.0, when Redis is executed with the default configuration (binding all the interfaces) and without any password in order to access it, it enters a special mode called protected mode. In this mode Redis only replies to queries from the loopback interfaces, and reply to other clients connecting from other addresses with an error, explaining what is happening and how to configure Redis properly.
We expect protected mode to seriously decrease the security issues caused by unprotected Redis instances executed without proper administration, however the system administrator can still ignore the error given by Redis and just disable protected mode or manually bind all the interfaces.
Quelle: https://redis.io/topics/securitySomit kann man die Instanz von Redis nur über 127.0.0.1 erreichen.