Freier Linux GPU Treiber
ROCKPro64
1
Beiträge
1
Kommentatoren
543
Aufrufe
-
Da arbeitet jemand an was, was man evt. mal auf dem ROCKPro64 nutzen kann.
Seit mehr als einem Jahr entsteht per Reverse-Engineering ein freier Linux-Grafiktreiber für die Midgard genannte Architektur-Generation von ARMs Mali-GPUs. Entwickelt wird der Treiber, der inzwischen Panfrost heißt, von Alyssa Rosenzweig mit Unterstützung aus der Community.
-
-
-
-
-
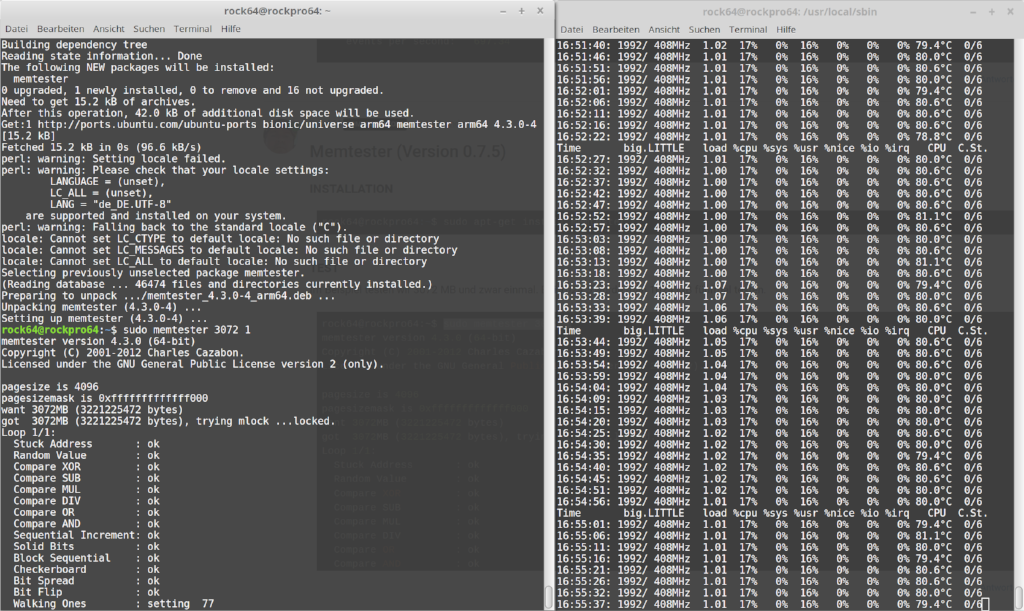
Mainline Kernel 4.20.x
Verschoben Images -
Lokale Einstellungen
Verschoben ROCKPro64 -
-