Your browser does not seem to support JavaScript. As a result, your viewing experience will be diminished, and you have been placed in read-only mode.
Please download a browser that supports JavaScript, or enable it if it's disabled (i.e. NoScript).
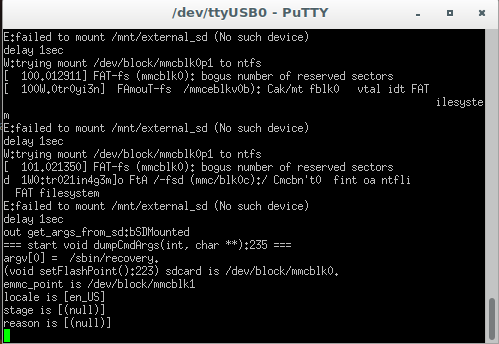
Erste Lebenszeichen
Gut zu wissen, die Kiste lebt. Yeah!

")

