ROCKPro64 - SD-Karte
Hardware
1
Beiträge
1
Kommentatoren
563
Aufrufe
-
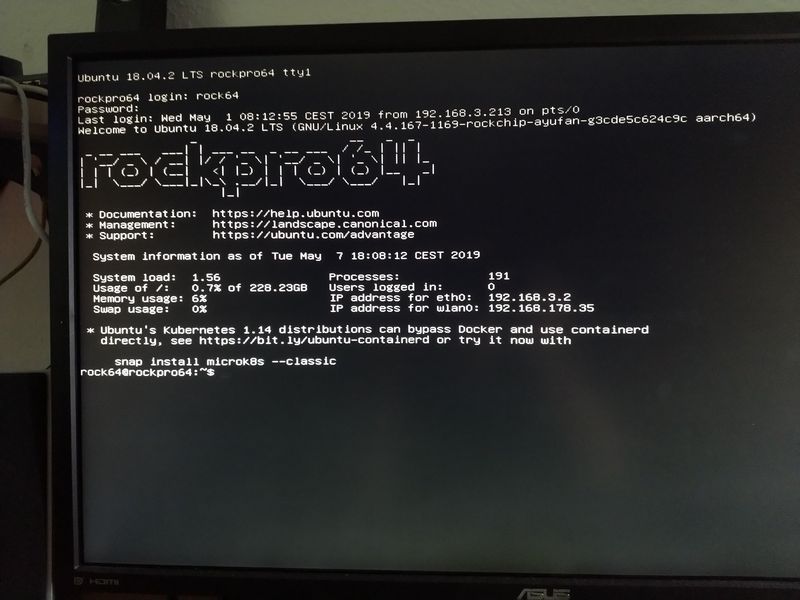
Seit 0.7.7 bzw. 4.18.0-rc3-1046-ayufan kann man nun eine geeignete SD-Karte im SDR104 Modus betreiben.
(20:12:27) ayufan1: basically speeds up to 100MB/s
(20:12:39) ayufan1: useful if you have evo+ samsung card
(20:12:46) ayufan1: which can easily reach 70-80MB/srock64@rockpro64:~$ dmesg | grep SDR [ 3.810014] mmc0: new ultra high speed SDR104 SDHC card at address aaaa
-
-
-
-
-
-
-
Mainline Kernel 4.17-rc7
Verschoben Archiv -