Python3 - enumerate()
Python3
2
Beiträge
1
Kommentatoren
198
Aufrufe
-
Heute mal wieder was aus der Rubtik "Coden für Anfänger"
")
Am Anfang hatte ich mit verschiedenen Aufgaben, so meine Probleme.
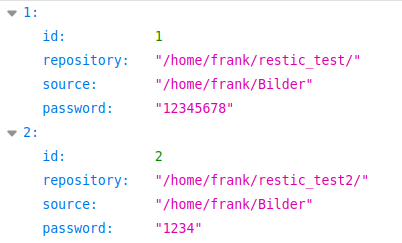
x = 0 for _ in keys_list: mainWin.listWidget.addItem(backup_data[x].name) x += 1Ich habe eine Liste, die die Datensätze in meiner JSON Datei darstellen soll. Beispiel
['1', '7', '8', '9', '10']So sieht ein Teil meiner JSON-Datei aus
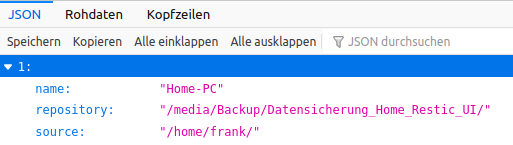
Es gibt weitere Datensätze mit der Nummer 7,8,9 und 10. Diese Daten verwalte ich in einer Liste namens keys_list. Wenn ich die Daten ausgebe, sieht das aus.
0 1 1 7 2 8 3 9 4 10Hier sieht man die Datensätze, die durchnummeriert werden. Die Datensätze der JSON-Datei lade ich bei Programmstart und erzeuge eine Klasse und fülle diese mit Objekten. Dazu muss ich aber wissen, wie viele Datensätze vorhanden sind. Also zählen wir die Einträge durch.
Da ich im Python Forum immer sehr aufmerksam mitlese, habe ich dort erfahren, das man das wie ganz oben so nicht macht. Das kann man besser mit der Funktion enumerate() lösen.
for count, value in enumerate(keys_list): mainWin.listWidget.addItem(backup_data[count].name) print(count, value)Hier das Beispiel von oben, umgesetzt mit der Funktion enumerate(). Man spart sich die Variable x, das erledigt die Funktion von alleine. Der Code von oben hat 4 Zeilen, mit enumerate() hat er nur noch 2 Zeilen. (print Anweisung nicht berücksichtigt). Der Code ist schlanker und subjektiv auch besser lesbar.
-
Ich habe noch was Code gefunden, den ich mal dringend aufräumen musste
") Wenn ich mit dem Restic UI die Snapshots anzeige, dann sieht das so aus.
Wenn ich mit dem Restic UI die Snapshots anzeige, dann sieht das so aus.reading repository password from stdin ID Time Host Tags Paths ---------------------------------------------------------------------------- 4e769748 2021-12-31 21:48:34 frank-MS-7C37 /home/frank/Bilder 34298934 2022-01-26 20:15:53 frank-MS-7C37 /home/frank/Bilder 0d5d88f2 2022-01-27 21:05:07 frank-MS-7C37 /home/frank/Bilder f0e7d5a7 2022-01-29 13:46:12 frank-MS-7C37 /home/frank/Bilder 79918d70 2022-01-29 13:52:56 frank-MS-7C37 /home/frank/Bilder d74272a3 2022-01-30 11:54:20 frank-MS-7C37 /home/frank/Bilder 11b0b5ad 2022-01-30 11:57:44 frank-MS-7C37 /home/frank/Bilder 4a7450d2 2022-02-20 09:35:56 frank-MS-7C37 /home/frank/Bilder c1a4a51d 2022-02-20 09:36:43 frank-MS-7C37 /home/frank/Bilder d178ded5 2022-02-20 09:38:53 frank-MS-7C37 /home/frank/Bilder 997e2259 2022-02-20 16:35:57 frank-MS-7C37 /home/frank/Bilder 3320ad5c 2022-02-20 16:49:19 frank-MS-7C37 /home/frank/Bilder ---------------------------------------------------------------------------- 12 snapshotsMich interessieren die IDs, weil ich bei der Eingabe der IDs überprüfen möchte, ob die eingegebene ID existiert. Also muss ich das irgendwie auslesen und speichern. Das habe ich bis jetzt so gemacht.
def id_append(self, result): # We split the result into individual lines. # Result was passed. And create an list. result_list = result.split('\n') # We count the number of repositories and search for 'source'. count = result.count(backup_data[row].source) # Offset added, first interesting line is line 3! count = count + 3 # We loop through the list and output the ID's and store in snapshot_id x = 3 while x < count: a = result_list[x] y = a[0:8] snapshot_id.append(y) x = x + 1Das erschien mir heute, beim erneuten Betrachten, Spaghetticode zu sein. Machen wir das mal etwas ordentlicher.
Ich nehme die Ausgabe (stdout) und erzeuge eine Liste, jede Zeile ein Element.
result_list = result.split('\n')Sieht so aus
['reading repository password from stdin', 'ID Time Host Tags Paths', '----------------------------------------------------------------------------', '4e769748 2021-12-31 21:48:34 frank-MS-7C37 /home/frank/Bilder', '34298934 2022-01-26 20:15:53 frank-MS-7C37 /home/frank/Bilder', '0d5d88f2 2022-01-27 21:05:07 frank-MS-7C37 /home/frank/Bilder', 'f0e7d5a7 2022-01-29 13:46:12 frank-MS-7C37 /home/frank/Bilder', '79918d70 2022-01-29 13:52:56 frank-MS-7C37 /home/frank/Bilder', 'd74272a3 2022-01-30 11:54:20 frank-MS-7C37 /home/frank/Bilder', '11b0b5ad 2022-01-30 11:57:44 frank-MS-7C37 /home/frank/Bilder', '4a7450d2 2022-02-20 09:35:56 frank-MS-7C37 /home/frank/Bilder', 'c1a4a51d 2022-02-20 09:36:43 frank-MS-7C37 /home/frank/Bilder', 'd178ded5 2022-02-20 09:38:53 frank-MS-7C37 /home/frank/Bilder', '997e2259 2022-02-20 16:35:57 frank-MS-7C37 /home/frank/Bilder', '3320ad5c 2022-02-20 16:49:19 frank-MS-7C37 /home/frank/Bilder', '----------------------------------------------------------------------------', '12 snapshots', '']Diesmal benutzen wir die enumerate() Funktion
for count, value in enumerate(result_list): print(count, value)Das was raus kommt, sieht so aus
0 reading repository password from stdin 1 ID Time Host Tags Paths 2 ---------------------------------------------------------------------------- 3 4e769748 2021-12-31 21:48:34 frank-MS-7C37 /home/frank/Bilder 4 34298934 2022-01-26 20:15:53 frank-MS-7C37 /home/frank/Bilder 5 0d5d88f2 2022-01-27 21:05:07 frank-MS-7C37 /home/frank/Bilder 6 f0e7d5a7 2022-01-29 13:46:12 frank-MS-7C37 /home/frank/Bilder 7 79918d70 2022-01-29 13:52:56 frank-MS-7C37 /home/frank/Bilder 8 d74272a3 2022-01-30 11:54:20 frank-MS-7C37 /home/frank/Bilder 9 11b0b5ad 2022-01-30 11:57:44 frank-MS-7C37 /home/frank/Bilder 10 4a7450d2 2022-02-20 09:35:56 frank-MS-7C37 /home/frank/Bilder 11 c1a4a51d 2022-02-20 09:36:43 frank-MS-7C37 /home/frank/Bilder 12 d178ded5 2022-02-20 09:38:53 frank-MS-7C37 /home/frank/Bilder 13 997e2259 2022-02-20 16:35:57 frank-MS-7C37 /home/frank/Bilder 14 3320ad5c 2022-02-20 16:49:19 frank-MS-7C37 /home/frank/Bilder 15 ---------------------------------------------------------------------------- 16 12 snapshots 17Mich interessieren nur die Zeilen mit /home/frank/Bilder Das kann man so abfragen
if backup_data[row].source in value:Und jetzt nur die ID entsprechend abspeichern
snapshot_id.append(value[0:8])Sieht jetzt komplett so aus
result_list = result.split('\n') for count, value in enumerate(result_list): if backup_data[row].source in value: snapshot_id.append(value[0:8]) print(count, value[0:8])Somit speichert er jetzt nur noch die IDs, der folgenden Ausgabe.
3 4e769748 4 34298934 5 0d5d88f2 6 f0e7d5a7 7 79918d70 8 d74272a3 9 11b0b5ad 10 4a7450d2 11 c1a4a51d 12 d178ded5 13 997e2259 14 3320ad5cDiese IDs, kann ich dann weiterverarbeiten.