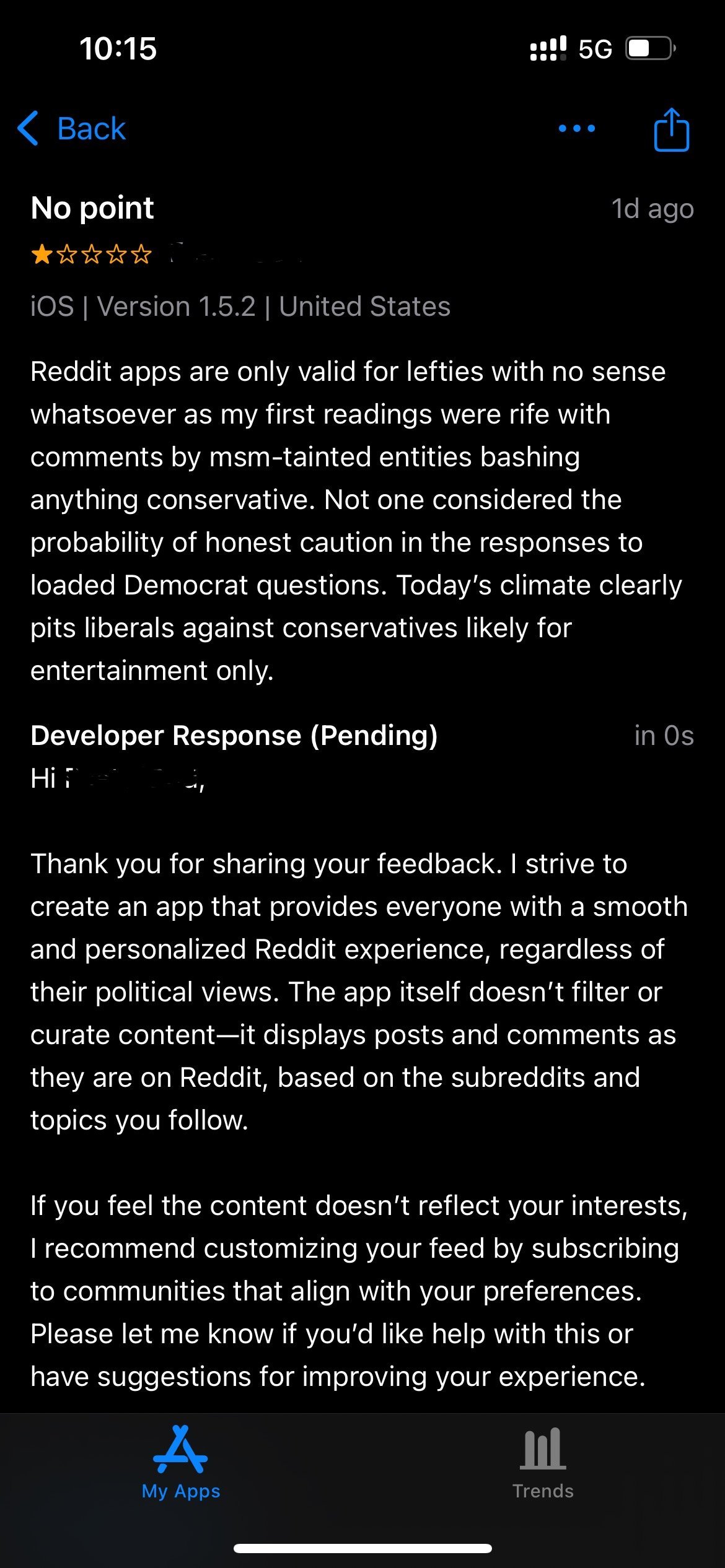
Wikipedia Pauses an Experiment That Showed Users AI-Generated Summaries at The Top of Some Articles, Following an Editor Backlash.
Technology
40
Beiträge
30
Kommentatoren
1
Aufrufe
-
Grok please ELI5 this comment so i can understand it
I know your comment was /s bit I cant not repost this:

-
Hey everyone, this is Olga, the product manager for the summary feature again. Thank you all for engaging so deeply with this discussion and sharing your thoughts so far.
Reading through the comments, it’s clear we could have done a better job introducing this idea and opening up the conversation here on VPT back in March. As internet usage changes over time, we are trying to discover new ways to help new generations learn from Wikipedia to sustain our movement into the future. In consequence, we need to figure out how we can experiment in safe ways that are appropriate for readers and the Wikimedia community. Looking back, we realize the next step with this message should have been to provide more of that context for you all and to make the space for folks to engage further. With that in mind, we’d like to take a step back so we have more time to talk through things properly. We’re still in the very early stages of thinking about a feature like this, so this is actually a really good time for us to discuss here.
A few important things to start with:
- Bringing generative AI into the Wikipedia reading experience is a serious set of decisions, with important implications, and we intend to treat it as such.
- We do not have any plans for bringing a summary feature to the wikis without editor involvement. An editor moderation workflow is required under any circumstances, both for this idea, as well as any future idea around AI summarized or adapted content.
- With all this in mind, we’ll pause the launch of the experiment so that we can focus on this discussion first and determine next steps together.
We’ve also started putting together some context around the main points brought up through the conversation so far, and will follow-up with that in separate messages so we can discuss further.
I don't see how AI could benefit wikipedia. Just the power consumption alone isn't worth it. Wiki is one of the rare AI free zones, which is a reason why it is good
-
Hey everyone, this is Olga, the product manager for the summary feature again. Thank you all for engaging so deeply with this discussion and sharing your thoughts so far.
Reading through the comments, it’s clear we could have done a better job introducing this idea and opening up the conversation here on VPT back in March. As internet usage changes over time, we are trying to discover new ways to help new generations learn from Wikipedia to sustain our movement into the future. In consequence, we need to figure out how we can experiment in safe ways that are appropriate for readers and the Wikimedia community. Looking back, we realize the next step with this message should have been to provide more of that context for you all and to make the space for folks to engage further. With that in mind, we’d like to take a step back so we have more time to talk through things properly. We’re still in the very early stages of thinking about a feature like this, so this is actually a really good time for us to discuss here.
A few important things to start with:
- Bringing generative AI into the Wikipedia reading experience is a serious set of decisions, with important implications, and we intend to treat it as such.
- We do not have any plans for bringing a summary feature to the wikis without editor involvement. An editor moderation workflow is required under any circumstances, both for this idea, as well as any future idea around AI summarized or adapted content.
- With all this in mind, we’ll pause the launch of the experiment so that we can focus on this discussion first and determine next steps together.
We’ve also started putting together some context around the main points brought up through the conversation so far, and will follow-up with that in separate messages so we can discuss further.
I don't think Wikipedia is for the benefit of users anymore, what even are the alternatives? Leftypedia? Definitely not Britannica
-
I know your comment was /s bit I cant not repost this:
Hahaha i too have that saved. I love it so much.
-
Hey everyone, this is Olga, the product manager for the summary feature again. Thank you all for engaging so deeply with this discussion and sharing your thoughts so far.
Reading through the comments, it’s clear we could have done a better job introducing this idea and opening up the conversation here on VPT back in March. As internet usage changes over time, we are trying to discover new ways to help new generations learn from Wikipedia to sustain our movement into the future. In consequence, we need to figure out how we can experiment in safe ways that are appropriate for readers and the Wikimedia community. Looking back, we realize the next step with this message should have been to provide more of that context for you all and to make the space for folks to engage further. With that in mind, we’d like to take a step back so we have more time to talk through things properly. We’re still in the very early stages of thinking about a feature like this, so this is actually a really good time for us to discuss here.
A few important things to start with:
- Bringing generative AI into the Wikipedia reading experience is a serious set of decisions, with important implications, and we intend to treat it as such.
- We do not have any plans for bringing a summary feature to the wikis without editor involvement. An editor moderation workflow is required under any circumstances, both for this idea, as well as any future idea around AI summarized or adapted content.
- With all this in mind, we’ll pause the launch of the experiment so that we can focus on this discussion first and determine next steps together.
We’ve also started putting together some context around the main points brought up through the conversation so far, and will follow-up with that in separate messages so we can discuss further.
If they thought this would be well-received they wouldn't have sprung it on people. The fact that they're only "pausing the launch of the experiment" means they're going to do it again once the backlash has subsided.
RIP Wikipedia, it was a fun 24 years.
-
If they thought this would be well-received they wouldn't have sprung it on people. The fact that they're only "pausing the launch of the experiment" means they're going to do it again once the backlash has subsided.
RIP Wikipedia, it was a fun 24 years.
Not everything is black and white, you know. Just because they have this blunder, doesn't mean they're down for good. The fact they're willing to listen to feedback, whatever their reason was, still shows some good sign.
Also keep in mind the organization than runs it has a lot of people, each with their own agenda, some with bad ones but extremely useful.
I mean yeah, sure, do 'leave' Wikipedia if you want. I'm curious to where you'd go.
-
Hey everyone, this is Olga, the product manager for the summary feature again. Thank you all for engaging so deeply with this discussion and sharing your thoughts so far.
Reading through the comments, it’s clear we could have done a better job introducing this idea and opening up the conversation here on VPT back in March. As internet usage changes over time, we are trying to discover new ways to help new generations learn from Wikipedia to sustain our movement into the future. In consequence, we need to figure out how we can experiment in safe ways that are appropriate for readers and the Wikimedia community. Looking back, we realize the next step with this message should have been to provide more of that context for you all and to make the space for folks to engage further. With that in mind, we’d like to take a step back so we have more time to talk through things properly. We’re still in the very early stages of thinking about a feature like this, so this is actually a really good time for us to discuss here.
A few important things to start with:
- Bringing generative AI into the Wikipedia reading experience is a serious set of decisions, with important implications, and we intend to treat it as such.
- We do not have any plans for bringing a summary feature to the wikis without editor involvement. An editor moderation workflow is required under any circumstances, both for this idea, as well as any future idea around AI summarized or adapted content.
- With all this in mind, we’ll pause the launch of the experiment so that we can focus on this discussion first and determine next steps together.
We’ve also started putting together some context around the main points brought up through the conversation so far, and will follow-up with that in separate messages so we can discuss further.
Since much (so-called) "AI" basic training data depends on Wikipedia, wouldn't this create a feedback loop that could quickly degenerate ?
-
Hey everyone, this is Olga, the product manager for the summary feature again. Thank you all for engaging so deeply with this discussion and sharing your thoughts so far.
Reading through the comments, it’s clear we could have done a better job introducing this idea and opening up the conversation here on VPT back in March. As internet usage changes over time, we are trying to discover new ways to help new generations learn from Wikipedia to sustain our movement into the future. In consequence, we need to figure out how we can experiment in safe ways that are appropriate for readers and the Wikimedia community. Looking back, we realize the next step with this message should have been to provide more of that context for you all and to make the space for folks to engage further. With that in mind, we’d like to take a step back so we have more time to talk through things properly. We’re still in the very early stages of thinking about a feature like this, so this is actually a really good time for us to discuss here.
A few important things to start with:
- Bringing generative AI into the Wikipedia reading experience is a serious set of decisions, with important implications, and we intend to treat it as such.
- We do not have any plans for bringing a summary feature to the wikis without editor involvement. An editor moderation workflow is required under any circumstances, both for this idea, as well as any future idea around AI summarized or adapted content.
- With all this in mind, we’ll pause the launch of the experiment so that we can focus on this discussion first and determine next steps together.
We’ve also started putting together some context around the main points brought up through the conversation so far, and will follow-up with that in separate messages so we can discuss further.
It does sound like it could be handy
-
So they:
- Didn't ask editors/users
- noticed loud and overwhelmingly negative feedback
- "paused" the program
They still don't get it. There's very little practical use for LLMs in general, and certainly not in scholastic spaces. The content is all user-generated anyway, so what's even the point? It's not saving them any money.
Also it seems like a giant waste of resources for a company that constantly runs giant banners asking for money and claiming to basically be on there verge of closing up every time you visit their site.
I also think that generating blob summaries just goes towards brain rot things we see everywhere on the web that's just destroying people's attention spam. Wikipedia is kind of good to read something that is long enough and not just some quick, simplistic and brain rotting inducing blob
-
Not everything is black and white, you know. Just because they have this blunder, doesn't mean they're down for good. The fact they're willing to listen to feedback, whatever their reason was, still shows some good sign.
Also keep in mind the organization than runs it has a lot of people, each with their own agenda, some with bad ones but extremely useful.
I mean yeah, sure, do 'leave' Wikipedia if you want. I'm curious to where you'd go.
the fact they're willing to listen to feedback, whatever their reason was, is a good sign
Oh you have so much to learn about companies fucking their users over if you think this is the end of them trying to shove AI into Wikipedia
-
the fact they're willing to listen to feedback, whatever their reason was, is a good sign
Oh you have so much to learn about companies fucking their users over if you think this is the end of them trying to shove AI into Wikipedia
Then teach me daddy~
-
Hey everyone, this is Olga, the product manager for the summary feature again. Thank you all for engaging so deeply with this discussion and sharing your thoughts so far.
Reading through the comments, it’s clear we could have done a better job introducing this idea and opening up the conversation here on VPT back in March. As internet usage changes over time, we are trying to discover new ways to help new generations learn from Wikipedia to sustain our movement into the future. In consequence, we need to figure out how we can experiment in safe ways that are appropriate for readers and the Wikimedia community. Looking back, we realize the next step with this message should have been to provide more of that context for you all and to make the space for folks to engage further. With that in mind, we’d like to take a step back so we have more time to talk through things properly. We’re still in the very early stages of thinking about a feature like this, so this is actually a really good time for us to discuss here.
A few important things to start with:
- Bringing generative AI into the Wikipedia reading experience is a serious set of decisions, with important implications, and we intend to treat it as such.
- We do not have any plans for bringing a summary feature to the wikis without editor involvement. An editor moderation workflow is required under any circumstances, both for this idea, as well as any future idea around AI summarized or adapted content.
- With all this in mind, we’ll pause the launch of the experiment so that we can focus on this discussion first and determine next steps together.
We’ve also started putting together some context around the main points brought up through the conversation so far, and will follow-up with that in separate messages so we can discuss further.
Lol, the source data for all AI is starting to use AI to summarize.
Have you ever tried to zip a zipfile?
But then on the other hand, as compilers become better, they become more efficient at compiling their own source code...
-
The sad truth is that AI empowers the malicious to create a bigger impact on workload and standards than is scalable with humans alone. An AI running triage on article changes that flags or reports changes which need more input would be ideal. But threat mitigation and integrity preservation don't really seem to be high on their priorities.
Nope, they're just interested in colonizing every single second of our time with "info"-tainment on par with the intellectual capacity of Harlequin romances.
-
Not everything is black and white, you know. Just because they have this blunder, doesn't mean they're down for good. The fact they're willing to listen to feedback, whatever their reason was, still shows some good sign.
Also keep in mind the organization than runs it has a lot of people, each with their own agenda, some with bad ones but extremely useful.
I mean yeah, sure, do 'leave' Wikipedia if you want. I'm curious to where you'd go.
Me saying "RIP" was an attempt at hyperbole. That being said, shoehorning AI into something for which a big selling point is that it's user-made is a gigantic misstep - Maybe they'll listen to everybody, but given that they tried it at all, I can't see them properly backing down. Especially when it was worded as "pausing" the experiment.
-
Lol, the source data for all AI is starting to use AI to summarize.
Have you ever tried to zip a zipfile?
But then on the other hand, as compilers become better, they become more efficient at compiling their own source code...
Yeah but the compilers compile improved versions. Like, if you manually curated the summaries to be even better, then fed it to AI to produce a new summary you also curate... you'll end up with a carefully hand-trained LLM.
-
Yeah but the compilers compile improved versions. Like, if you manually curated the summaries to be even better, then fed it to AI to produce a new summary you also curate... you'll end up with a carefully hand-trained LLM.
So if the AI generated summaries are better than man made summaries, this would not be an issue would it?
-
So if the AI generated summaries are better than man made summaries, this would not be an issue would it?
If AI constantly refined its own output, sure, unless it hits a wall eventually or starts spewing bullshit because of some quirk of training. But I doubt it could learn to summarise better without external input, just like a compiler won't produce a more optimised version of itself without human development work.