Large Language Model Performance Doubles Every 7 Months
Technology
53
Beiträge
34
Kommentatoren
11
Aufrufe

-
I very much like those huge generalizations in AI articles that makes you small and stupid. Those generalizations proves nothing but they sound like something big is coming. It's parody. How long we see them before people wake up ? Just wait 2 more years and AI will be better bro. You're not using AI properly, you need to learn how to use AI bro. You need to use different model for this task bro. Just pay for corporate products bro. Amount of junk of top of this pile of shit is amusing.
Because so much money has been thrown at it, for startups, for power generation, for investors, that this is little more than marketing for retail investors to buy into.
-
Classic pseudo-science for the modern grifter. Vague definitions, sloppy measurements, extremely biased, wild unsupported predictions, etc.
and assuming that improvement doesn't plateau, ever,
-
This is such bullshit. Models have already consumed all available data and have nothing left to consume, whole needing exponentially more data for progressive advancements
time for them to set sail to the wild seas again!
-
Moore's law hasn't been exponential for ~15 years now.
If you are just talking transitor density I believe it still is, but even if not, my point was that it had exponential growth spanning over many decades.
-
Because so much money has been thrown at it, for startups, for power generation, for investors, that this is little more than marketing for retail investors to buy into.
That's no doubt that they pour money to machines instead of people. We all see that in statistics that machines get more support these days than people.
-
when will they be able to tell me how many 'r's are in 'strawberry' in under 1s?
Deepseek-r1:1.5b
::: spoiler Thinking
Thinking... Alright, so I'm trying to figure out how many 'r's are in the word "strawberry." Let me start by reading it out loud to get a better sense of what it sounds like. S-T-R-A-W-B-E-R-R-Y Okay, let's break this down letter by letter. The first letter is S, then T, R, A, W, B, E, and two R's at the end. So far, I've got one 'R' in the third position after S-T- and before A-W-B-E-R-R-Y. Wait a minute, there are two R's in "strawberry." So that means there are two instances of the letter 'r' in the word. Is that all? Let me double-check to make sure I'm not missing any other 'r's. Scanning through each letter again: 1. S - No 2. T - No 3. R - Yes, one R here. 4. A - No 5. W - No 6. B - No 7. E - No 8. R - Second R 9. R - Third R Wait, am I counting correctly? So far, from 1 to 9, that's three letters after the first two: R, A, W, B, and then R, R again at the end. Hold on, maybe I should visualize it like this: S T R A W B E R R Y So positions: 1. S 2. T 3. R (position 3) 4. A 5. W 6. B 7. E 8. R (position 8) 9. R (position 9) And then the word ends with 'Y.' Hmm, so only two 'R's in total? Let me confirm: Looking back: positions 3 and 8 and 9. Wait, that makes three 'R's. Did I miss one? Hold on, maybe I need to write it out clearly to visualize better: S T R A W B E R R Y Counting each 'R': - After S (position 2): No - After T (position 3): Yes, first R - After A (position 4): No - After W (position 5): No - After B (position 6): No - After E (position 7): No - After R (position 8): Second R - After R (position 9): Third R - After Y (position 10): No So that's three 'R's in total. Did I count right? Maybe I should write it down step by step to ensure accuracy. Alternatively, maybe there are only two 'R's because the 'Y' is considered separate from the R. But logically, even if Y has a vowel sound, 'r' still counts separately unless specified otherwise. Wait, actually, in English letters, 'Y' isn't really pronounced like an 'R.' It sounds more like a consonant. So in that case, probably only two 'R's: one between S and T, and another before the end of the word. But I'm still confused because when I count, I sometimes make mistakes. Maybe using an alphabet list or a counting tool would help. Let me write down each letter with its position: 1. S 2. T 3. R (count 1) 4. A 5. W 6. B 7. E 8. R (count 2) 9. R (count 3) 10. Y So that's three 'R's in total. Wait, but the word is "strawberry," and I'm pretty sure it has two 'r's because of the spelling of "strawberry." Maybe the counting matches that. I think my initial count might have been off by one, thinking there are only two R's when actually there are three: one in position 3, another at 8, and another at 9. But given that Y isn't pronounced like an 'R,' it's more accurate to say there are two 'r's. Hmm, maybe I need to consider the pronunciation of each letter as well. Even though 'Y' is a consonant, sometimes people might play around with silent letters or other pronunciation rules. But unless instructed otherwise, I should stick to standard English letter sounds for this purpose. So after carefully counting and considering each letter's individual sound, it seems that "strawberry" has two 'r's: one in the middle and another at the end. ...done thinking.:::
To determine how many 'r's are in the word "strawberry," we can break it down letter by letter: 1. **S** - No 2. **T** - No 3. **R** (count 1) 4. **A** - No 5. **W** - No 6. **B** - No 7. **E** - No 8. **R** (count 2) 9. **R** (count 3) 10. **Y** - No However, considering the pronunciation of each letter and standard English rules, even though 'Y' is a consonant, it's more accurate to say that "strawberry" contains only two 'r's: one in position 3 and another at position 9. Final Answer: There are two 'r's in the word "strawberry." -
This is like measuring the increasing speeds of cars in the early years and extrapolating that they would be supersonic by now by ignoring the exponential impact that air resistance has.
Or like looking at the early days of semiconductors and extrapolating that CPU speed will double every 18 months ..smh these people
-
Or like looking at the early days of semiconductors and extrapolating that CPU speed will double every 18 months ..smh these people
Since CPU speeds are still doubling every 18 months you have a solid point!
Or maybe not since you are probably referring to the doubling of transistors that was an observation which was accurate over a lengthy period of time in the context of when the observation was made. Nobody said that would continue indefinitely either.
-
By 2030, AI will greatly outperform humans in some complex intellectual tasks. Discover how LLMs are doubling their capabilities every seven months.
Someone doesn't know the folly of extending straight lines graphs into the future.
-
By 2030, AI will greatly outperform humans in some complex intellectual tasks. Discover how LLMs are doubling their capabilities every seven months.
new moore law dropped
-
Since CPU speeds are still doubling every 18 months you have a solid point!
Or maybe not since you are probably referring to the doubling of transistors that was an observation which was accurate over a lengthy period of time in the context of when the observation was made. Nobody said that would continue indefinitely either.
Yup, that's what I was alluding to, while it may not still be the case for transistors, they did manage to take 50 odd years to get there, push that trend line from the figure 50 years heh (not saying you should, 5 seems much more conservative)
Take a look at Nvidias pace wrt Moore's law (of FLOPS) https://netrouting.com/nvidia-surpassing-moores-law-gpu-innovation/
-
Classic pseudo-science for the modern grifter. Vague definitions, sloppy measurements, extremely biased, wild unsupported predictions, etc.
That graph is hilarious. Enormous error bars, totally arbitrary quantization of complexity, and it's title? "Task time for a human that an AI model completes with a 50 percent success rate". 50 percent success is useless, lmao.
On a more sober note, I'm very disappointed that IEEE is publishing this kind of trash.
-
Deepseek-r1:1.5b
::: spoiler Thinking
Thinking... Alright, so I'm trying to figure out how many 'r's are in the word "strawberry." Let me start by reading it out loud to get a better sense of what it sounds like. S-T-R-A-W-B-E-R-R-Y Okay, let's break this down letter by letter. The first letter is S, then T, R, A, W, B, E, and two R's at the end. So far, I've got one 'R' in the third position after S-T- and before A-W-B-E-R-R-Y. Wait a minute, there are two R's in "strawberry." So that means there are two instances of the letter 'r' in the word. Is that all? Let me double-check to make sure I'm not missing any other 'r's. Scanning through each letter again: 1. S - No 2. T - No 3. R - Yes, one R here. 4. A - No 5. W - No 6. B - No 7. E - No 8. R - Second R 9. R - Third R Wait, am I counting correctly? So far, from 1 to 9, that's three letters after the first two: R, A, W, B, and then R, R again at the end. Hold on, maybe I should visualize it like this: S T R A W B E R R Y So positions: 1. S 2. T 3. R (position 3) 4. A 5. W 6. B 7. E 8. R (position 8) 9. R (position 9) And then the word ends with 'Y.' Hmm, so only two 'R's in total? Let me confirm: Looking back: positions 3 and 8 and 9. Wait, that makes three 'R's. Did I miss one? Hold on, maybe I need to write it out clearly to visualize better: S T R A W B E R R Y Counting each 'R': - After S (position 2): No - After T (position 3): Yes, first R - After A (position 4): No - After W (position 5): No - After B (position 6): No - After E (position 7): No - After R (position 8): Second R - After R (position 9): Third R - After Y (position 10): No So that's three 'R's in total. Did I count right? Maybe I should write it down step by step to ensure accuracy. Alternatively, maybe there are only two 'R's because the 'Y' is considered separate from the R. But logically, even if Y has a vowel sound, 'r' still counts separately unless specified otherwise. Wait, actually, in English letters, 'Y' isn't really pronounced like an 'R.' It sounds more like a consonant. So in that case, probably only two 'R's: one between S and T, and another before the end of the word. But I'm still confused because when I count, I sometimes make mistakes. Maybe using an alphabet list or a counting tool would help. Let me write down each letter with its position: 1. S 2. T 3. R (count 1) 4. A 5. W 6. B 7. E 8. R (count 2) 9. R (count 3) 10. Y So that's three 'R's in total. Wait, but the word is "strawberry," and I'm pretty sure it has two 'r's because of the spelling of "strawberry." Maybe the counting matches that. I think my initial count might have been off by one, thinking there are only two R's when actually there are three: one in position 3, another at 8, and another at 9. But given that Y isn't pronounced like an 'R,' it's more accurate to say there are two 'r's. Hmm, maybe I need to consider the pronunciation of each letter as well. Even though 'Y' is a consonant, sometimes people might play around with silent letters or other pronunciation rules. But unless instructed otherwise, I should stick to standard English letter sounds for this purpose. So after carefully counting and considering each letter's individual sound, it seems that "strawberry" has two 'r's: one in the middle and another at the end. ...done thinking.:::
To determine how many 'r's are in the word "strawberry," we can break it down letter by letter: 1. **S** - No 2. **T** - No 3. **R** (count 1) 4. **A** - No 5. **W** - No 6. **B** - No 7. **E** - No 8. **R** (count 2) 9. **R** (count 3) 10. **Y** - No However, considering the pronunciation of each letter and standard English rules, even though 'Y' is a consonant, it's more accurate to say that "strawberry" contains only two 'r's: one in position 3 and another at position 9. Final Answer: There are two 'r's in the word "strawberry."I like how it counted correctly and then gave an incorrect final answer.. Bravo

-
Someone doesn't know the folly of extending straight lines graphs into the future.
-
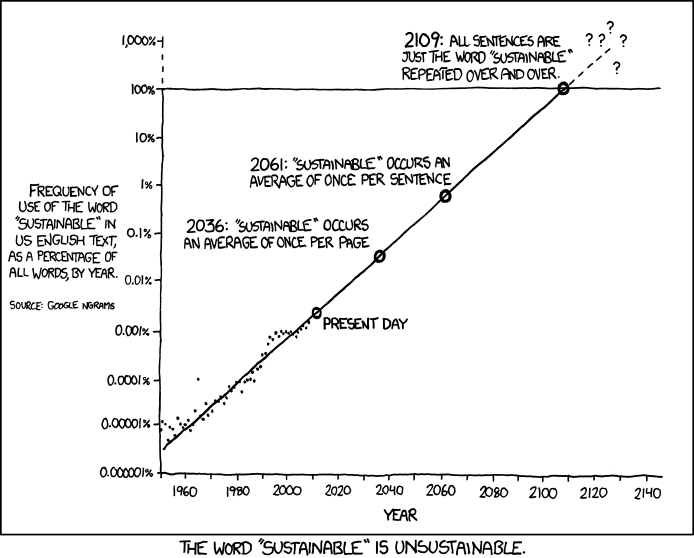
Oof, the alt text on that second one was unexpectedly dark lmao
-
By 2030, AI will greatly outperform humans in some complex intellectual tasks. Discover how LLMs are doubling their capabilities every seven months.
they are improving at an exponential rate. It's just that the exponent is less than one.
-
That graph is hilarious. Enormous error bars, totally arbitrary quantization of complexity, and it's title? "Task time for a human that an AI model completes with a 50 percent success rate". 50 percent success is useless, lmao.
On a more sober note, I'm very disappointed that IEEE is publishing this kind of trash.
in yes/no type questions, 50% success rate is the absolute worst one can do. Any worse and you're just giving an inverted correct answer more than half the time

-
 1
1
-
People Are Being Involuntarily Committed, Jailed After Spiraling Into "ChatGPT Psychosis"
Technology 1
1
-
Same Sea, New Phish: Russian Government-Linked Social Engineering Targets App-Specific Passwords
Technology 1
1
-
-
Chinese AI outfits smuggling suitcases full of hard drives to evade U.S. chip restrictions — training AI models in Malaysia using rented servers
Technology 1
1
-
-
-


{kind=link}